


Rasa2 NLU 架构及源码解析(一)
神州信息
李丹 郑飞 杜昕宸 韩彤 秦帅帅

Rasa是当前智能机器人中最流行的的聊天机器人框架,是基于机器学习和自然语言处理技术开发的系统,用于构建上下文AI助手和聊天机器人。
1.
背景
近年来,聊天机器人受到了学术界和工业界的广泛关注。人工智能技术的快速发展突破了聊天机器人原有的技术瓶颈,并且实践证明,聊天机器人的使用不仅能够为企业减少一大笔人力成本,而且能够明显提高工作效率,国内外多家企业纷纷布局聊天机器人行业。微软推出了基于情感计算的聊天机器人小冰,百度推出了用于交互式搜索的聊天机器人小度,进而推动了聊天机器人产品化的发展。聊天机器人系统可以看作是机器人产业与“互联网+”的结合,符合国家的科研及产业化发展方向。
随着人工智能在银行和金融科技的客户服务方面取得了重大改进,客户越来越习惯于获得快速响应。金融机构必须全天候回答客户问题和进行交易。金融机构业务扩展的加速使人工客服的成本大幅攀升的同时又无法持续满足服务质量,人工智能机器人通过金融机构长期积累的业务经验和数据培训聊天机器人,可明显改善客户体验。基于上述痛点和需求,各类聊天机器人框架应运而生。根据社区活跃度、技术的成熟完备度及被引用、点赞等指标,我们采用Rasa作为人机交互对话机器人基本框架。
2.
Rasa简介
Rasa Open Source有两个主要模块:
●Rasa NLU :用于理解用户消息,包括意图识别和实体识别。以pipeline的方式处理用户对话,可在config.yml中配置。
●Rasa Core:主要负责对话管理。根据NLU输出的信息、以及Tracker记录的历史信息,得到上下文的语境,从而预测用户当前步最可能执行哪一个action。
其中,Rasa NLU主要依赖自然语言处理技术,是可以独立的、与整体框架解耦的模块,可支持大量NLP前沿技术,以组件的形式,可以灵活与其他开源、自研框架搭配使用。
3.
Rasa NLU架构及源码解析
3.1 Rasa NLU概览
3.1.1 Rasa-NLU 架构图
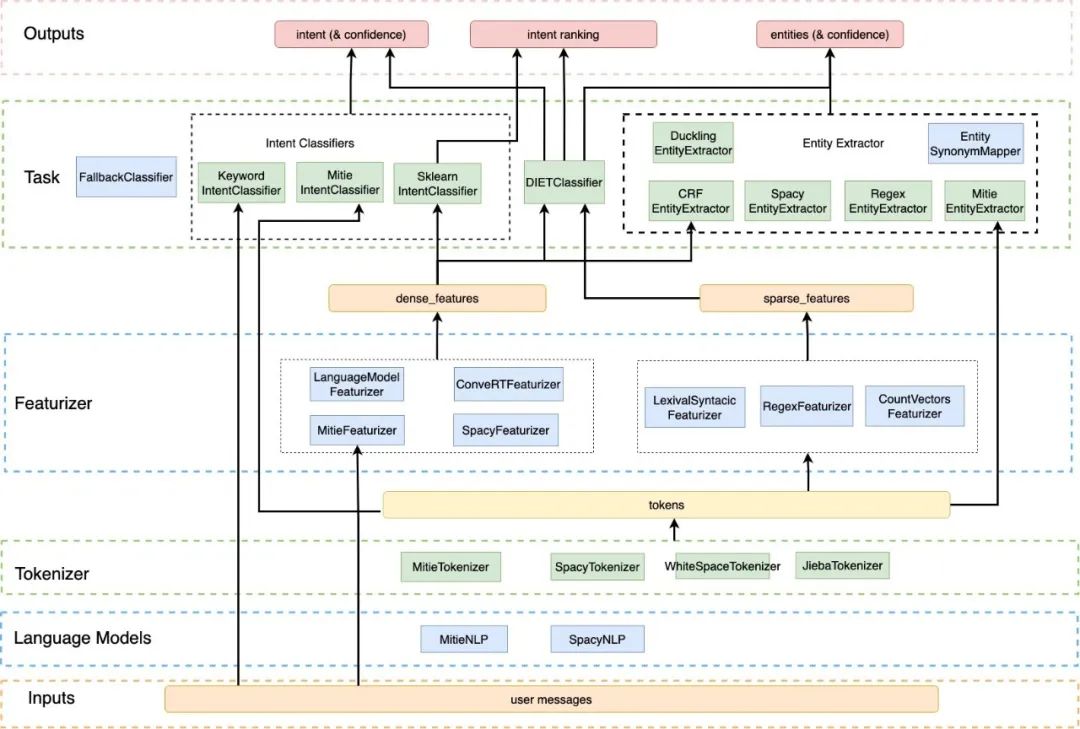
Rasa NLU 架构图
注:(1)FallbackClassifier应出现在某一个意图分类器之后,利用其输出的结果,即intent、confidence、intent ranking,如果意图的置信度比预设的threshold低,或排名前两位的意图的置信度的差距小于预设的ambiguity_threshold,则将该输入的意图分类为“nlu_fallback”
3.1.2 Rasa NLU训练流程
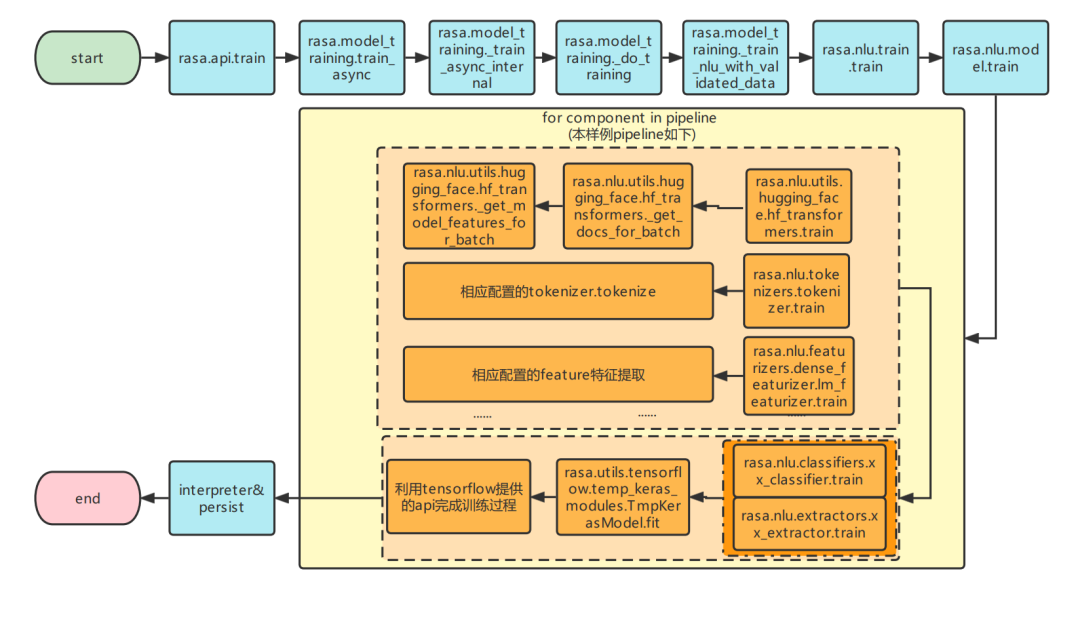
Rasa NLU训练流程图
rasa.model_training.train_async:
读取config, domain和训练data到file_importer: TrainingDataImporter, 并输入到_train_async_internal训练Rasa model (nlu and core).
rasa.model_training._train_async_internal:
判定模型需要重新训练的部分并将判定结果写入fingerprint_comparison作为_do_training方法的参数fingerprint_comparison_result的值输入_do_training完成相应部分的训练, 训练结束后将模型打包成trained_model,通过trained_model输入TrainingResult返回回至上层。
rasa.model_training._do_training:
通过fingerprint_comparison_result带入的结果判断是否重新训练nlu, core和nlg, 并进入相应模块进行训练。
rasa.model_training._train_nlu_with_validated_data:
按rasa.nlu.train.train各参数要求读取和整理参数值,输入rasa.nlu.train.train开始nlu模块的训练。
rasa.nlu.train.train:
通过初始化trainer=rasa.nlu.model.Trainer(...),构建config.yml中pipeline下的所有组件。读取TrainingDataImporter中的nlu数据后,将数据输入trainer.train开始训练。
rasa.nlu.model.Trainer.train:
遍历pipeline所有components,对每个component调用component.train方法完成训练。
3.1.3 Rasa NLU推理流程解析
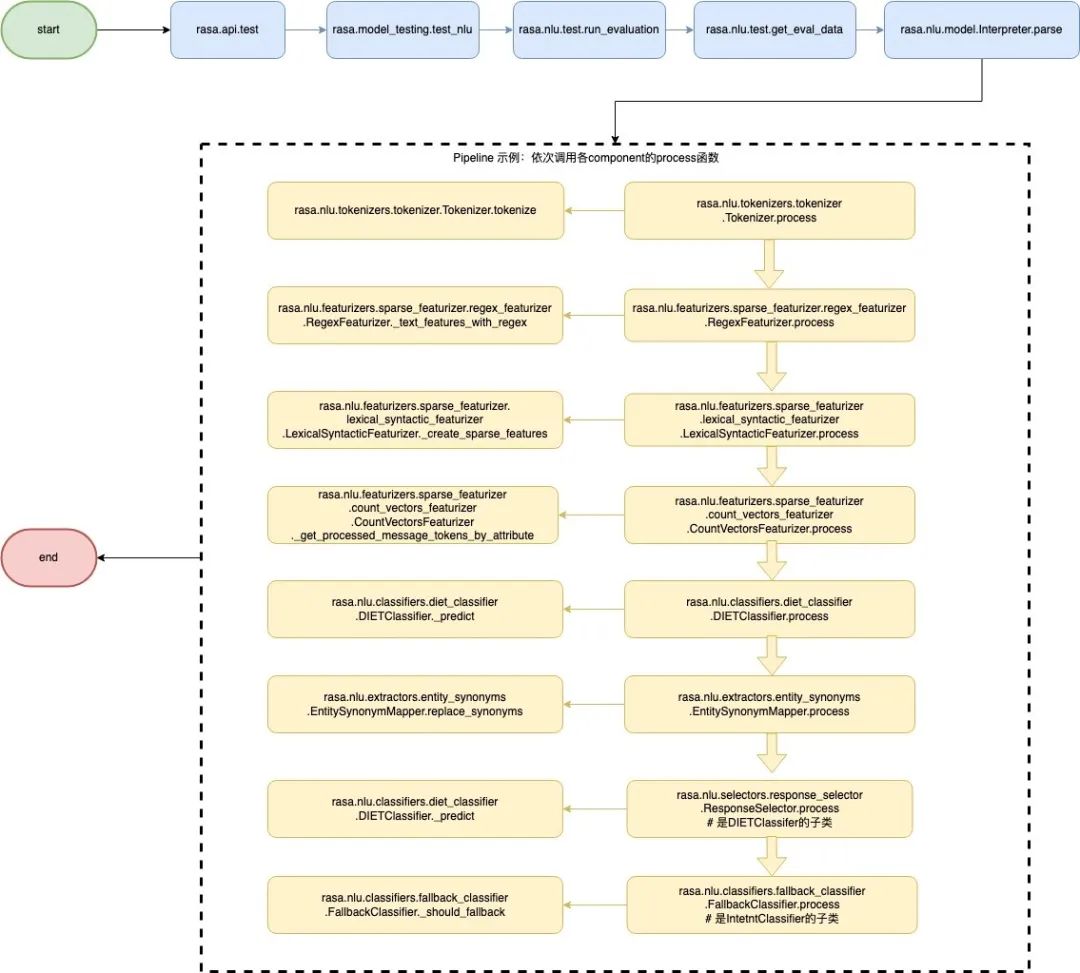
Rasa NLU推理流程图
rasa.model_testing.test_nlu:nlu测试入口,使用get_model函数加载model并解压(unpack),创建结果输出目录,调用测试过程
rasa.nlu.test.run_evaluation:测试过程入口函数,加载nlu模型初始化Interpreter实例,加载测试数据,调用get_eval_data进行测试
rasa.nlu.test.get_eval_data:在测试数据上运行模型,并提取真实标签和预测结果,输入interpreter实例和测试数据,返回意图测试结果(包括意图的标签和预测结果,原始消息,即message,及预测结果的置信度),response测试结果(包括response的目标值和预测结果),还有实体测试结果(实体的目标值,预测结果,和对应的token)
rasa.nlu.model.Interpreter.parse:一个interpreter对应一个训好的pipeline,其parse方法依次调用pipeline中的每一个component的process方法,来对输入文本一次进行解析和分类等操作,并返回处理结果(包括意图和实体)
每个component都有一个process入口方法,用于测试和实际预测,在process方法中再调用各component的内部方法(包含真正的处理逻辑),上图虚线框中即展示了一个基本的pipeline预测示例。
pipeline中Rasa自带的classifiers和extractors各组件(component)的具体介绍如下。
3.1 Classifier
3.1.1 Classifier架构
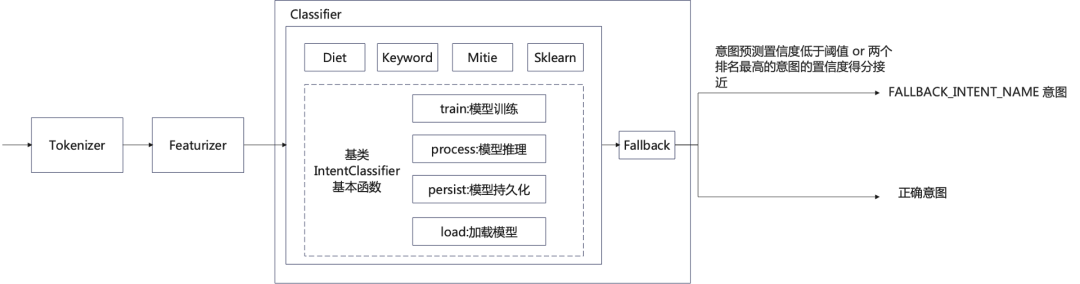
Rasa NLU Classifier 架构图
3.1.2 主流技术支持情况
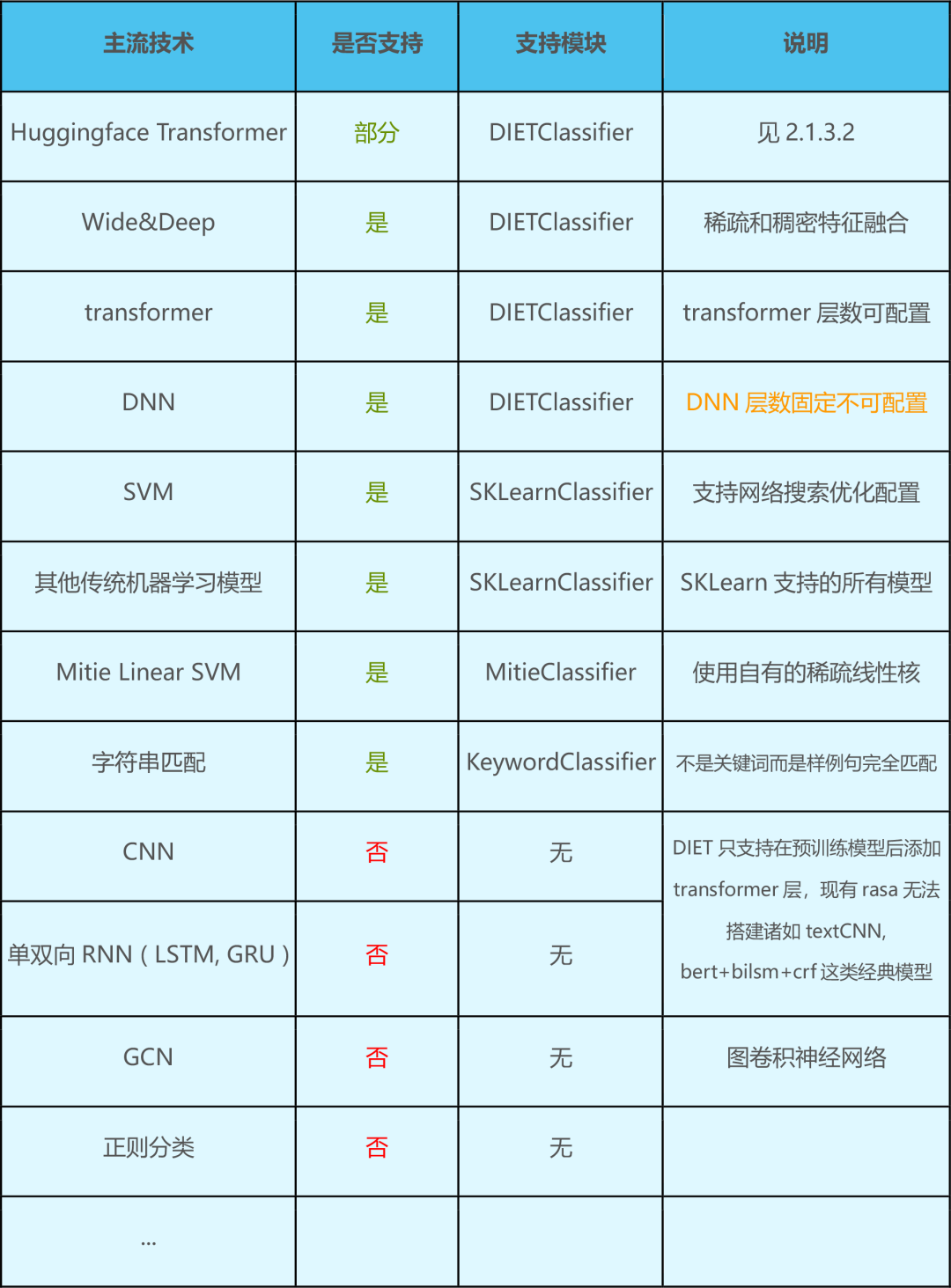
3.1.3 DIET Classifier
3.1.3.1 架构
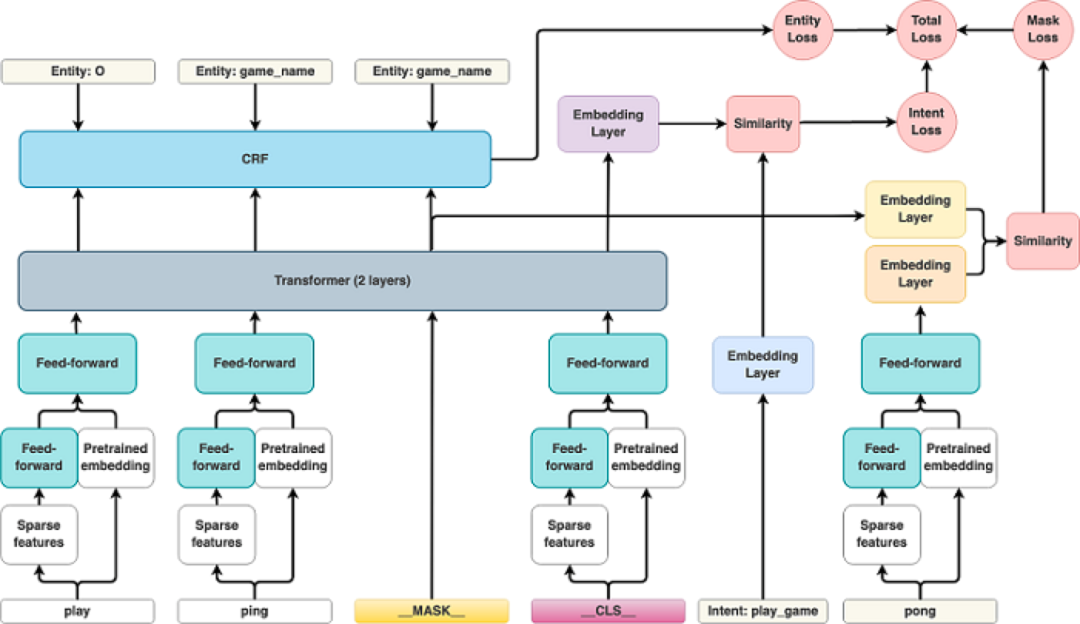
DIET ( Dual Intent and Entity Transformer ) 架构
3.1.3.2 模型支持说明
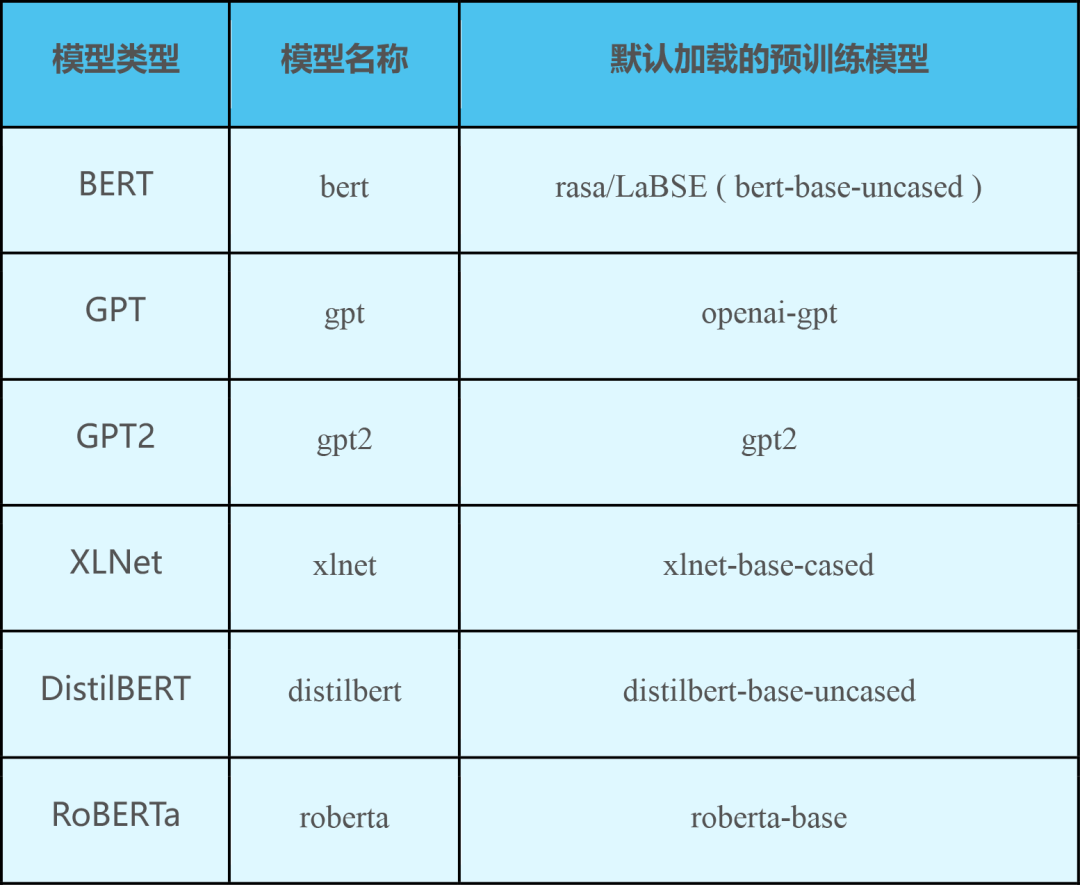
对在HuggingFace 中上传的所有预训练模型(Huggingface模型列表),Rasa DIET可以支持满足以下条件的所有模型:
点击Huggingface模型列表(https://huggingface.co/models?pipeline_tag=text-classification&sort=downloads)->选中一个模型->点击进入模型页面->点击Files and version
●检查 config.json 中的 model_type 是否列在上表的 模型名称 列中
●检查文件 tf_model.h5 是否存在
●模型使用默认tokenizer, config.json 中不包含支持自定义的 tokenizer_class
对满足上述条件的模型,通过2.1.3.3中描述的方式可开箱即用。
3.1.3.3 DIET支持Huggingface的配置样例
在Rasa2.0中,若想在DIET架构中使用Huggingface提供的预训练模型,除在rasa的config文件中指定使用DIETClassifier外,还需要配合使用对应的模块:
1) HFTransformersNLP
主要参数:model_name: 预训练模型config.json 中的 model_type的值;model_weights: Huggingface模型列表提供的预训练模型名称
2) LanguageModelTokenizer:确保训练数据token对应的token_id与预训练模型的token_id保持一致
3) LanguageModelFeaturizer:生成经预训练模型转换后的特征向量,做为架构后续模块的输入。

●DIET样例代码包位置:examples/hf_demo
●DIET样例代码调用方式:项目根目录/main.py
●涉及的源码改动:
如按 ‘样例代码调用方式’ 直接跑报错... set from_pt=true, 请修改: 项目根目录/rasa/nlu/utils/hugging_face/hf_transformers.py: class HFTransformersNLP中的def _load_model_instance中

改为

3.1.3.4 DIET核心代码解析
rasa.nlu.model.Trainer.train:遍历pipeline所有components,对每个component调用component.train方法完成训练。在component遍历到DIETClassifier之前,HFTransformersNLP等组件已经提取好了DIETClassifier训练需要的特征。遍历至DIETClassifier后,DIETClassifier开始利用已经提取好的特征进入训练。
rasa.nlu.classifiers.DIETClassifier.train: 该方法主要完成三件事:
●语料准备:
通过DIETClassifier类中的方法preprocess_train_data,将训练数据和之前提取的特征整理成符合RasaModelData格式的model_data。RasaModelData格式为。。。。。之后将整理好的model_data按batch_size整理成data_generator供batch训练用。
●指定模型:将DIETClassifier类的成员self.model通过初始化DIET类完成指定DIET模型训练。
■DIET模型类继承自TransformerRasaModel类
■TransformerRasaModel继承自RasaModel类
■RasaModel继承自TmpKerasModel:通过重写tf.keras.Model中的train_step(), test_step(), predict_step(), save()和load()方法,实现自定义的Rasa模型。
◆train_step()使用自定义的batch_loss并对该loss做了正则化。batch_loss需由其子类实现。
◆predict_step()使用自定义的batch_predict()。需由其子类实现。
◆save()只使用tf.keras.Model.save_weights()。
◆load()生成模型结构后加载weights.
■TmpKerasModel继承自tf.keras.models.Model:重写了tf.keras.models.Model的fit方法来使用自定义的数据适配器。将数据转写成CustomDataHandler后由其处理迭代 epoch 级别的 `tf.data.Iterator` 对象。
●训练
3.1.4 SKLearn Classifier
3.1.4.1 架构
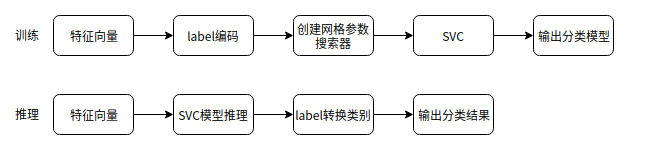
3.1.4.2 模型支持说明
Rasa 对 Sklearn中的所有分类器都支持,包括并不限于以下:

3.1.4.3 配置样例
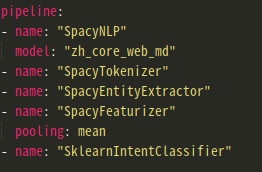

3.1.4.4 核心代码解析
LabelEncoder()函数:标签编码,类别标签数值化
transform_labels_str2num() 函数:标签到数值
transform_labels_() 函数:输入数值,输出标签文本
GridSearchCV() 函数:网格搜索参数,通过循环遍历,尝试每一种参数组合,返回最好的得分值的参数组合。
SVC() 函数:创建模型训练器
process()函数:模型推理
3.1.5 Mitie Classifier
3.1.5.1 架构
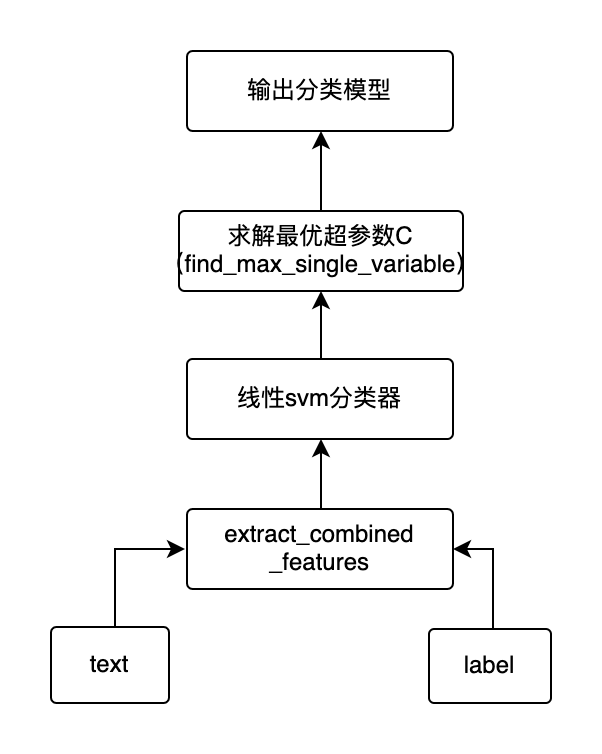
MitieIntentClassifier分类器使用MITIE进行意图分类,底层分类器使用的是具有稀疏线性核的多类线性支持向量机,MITIE是在dlib机器学习库之上开发的NLP工具包。其架构如下图:
3.1.5.2 模型支持说明
rasa Mitie Classifier目前只支持Mitie Classifier中具有稀疏线性核的多类线性支持向量机。适用于少样本数据的分类。
3.1.5.3 配置样例
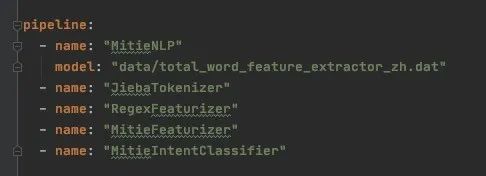
每个mitie组件都依赖与MitieNLP,因此它需要被放到pipeline中所有mitie组件之前,初始化mitie结构。
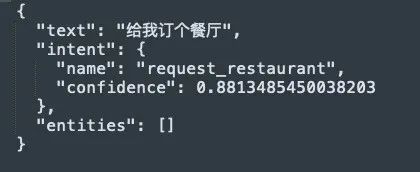
结果意图中没有intent_ranking,输出结果如下:
3.1.5.4 核心代码解析
训练代码流程图:
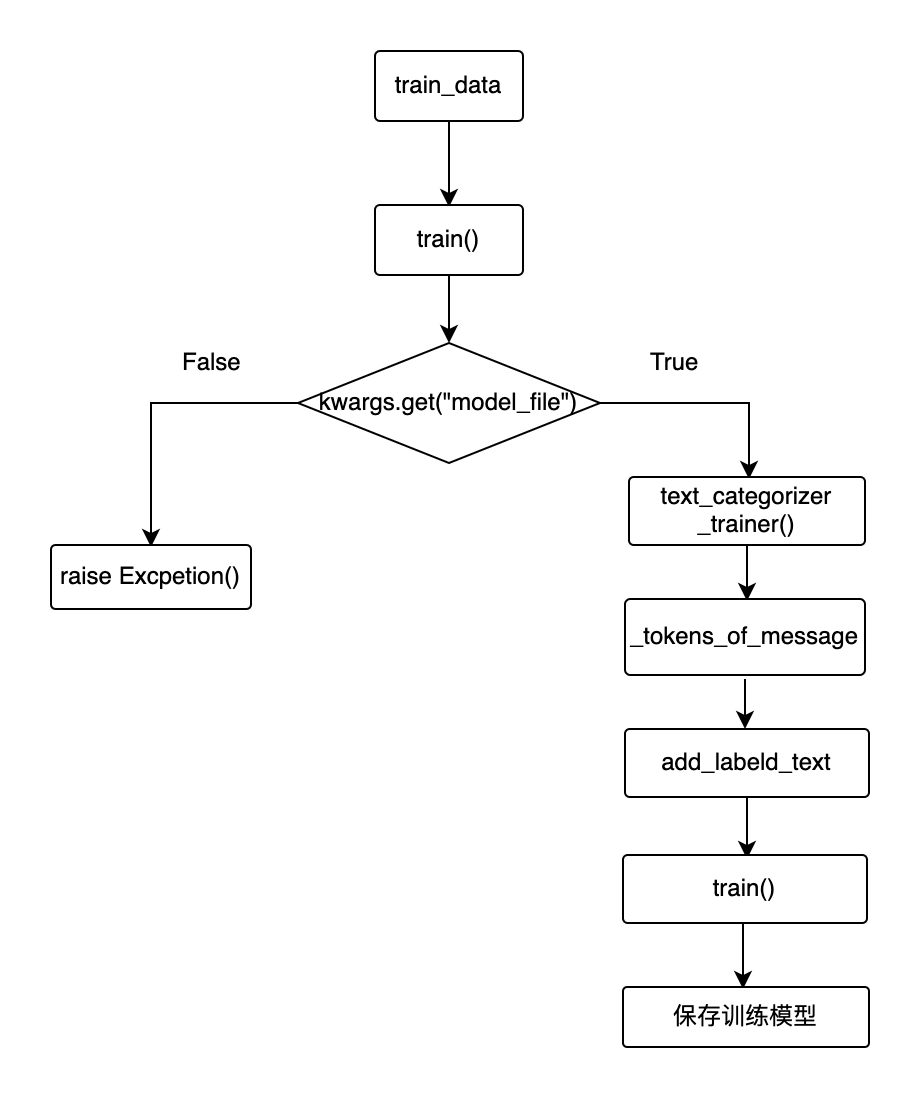
●训练数据输入到train
●获取预训练的词向量文件
●如果模型文件不存在则报错,否则实例化trainer
●把training_data.intent_examples中examples 转换成token
●添加token、intent到training instance
●训练,把训练模型保存
预测流程:
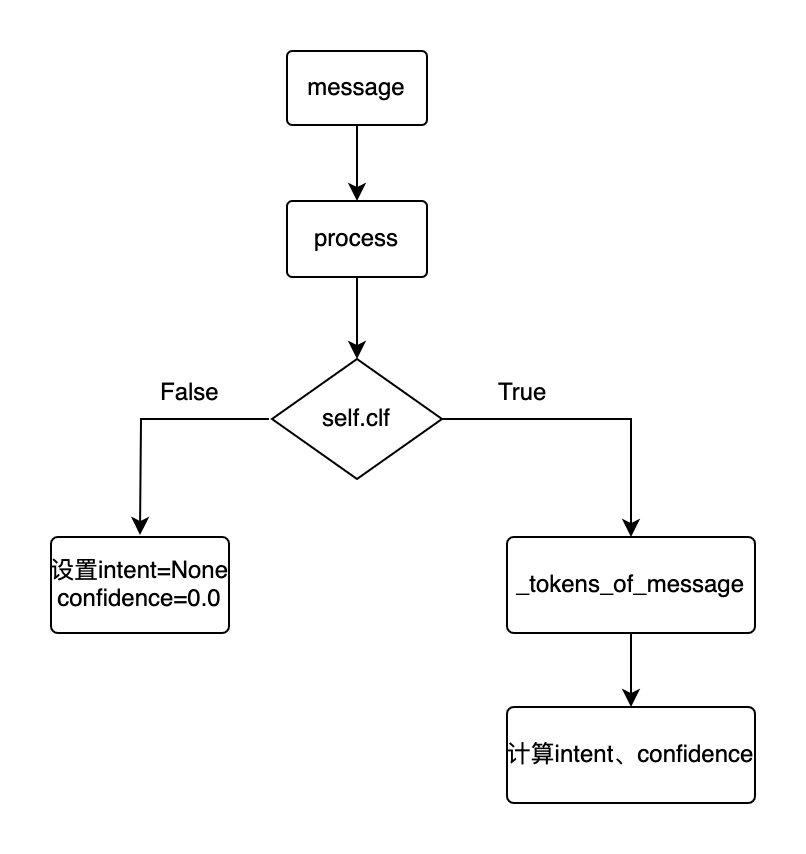
●用户message输入到process
●判断分类模型是否存在,若不存在则设置intent为None,confidence为0,否则,把message转成token,然后计算intent,confidence,并设置到message中
3.1.6 Keyword Classifier
3.1.6.1 工作机制
当训练集中的原句再次出现时,keyword意图分类器能够迅速对其分类。该分类器在训练过程中主动收集整理遇到的文本及对应意图,供后期使用时比对判断用。
3.1.6.2 使用样例
该分类器专门针对原句出现的场景,因此常常作为补充,与其他分类器配合使用,如下图。
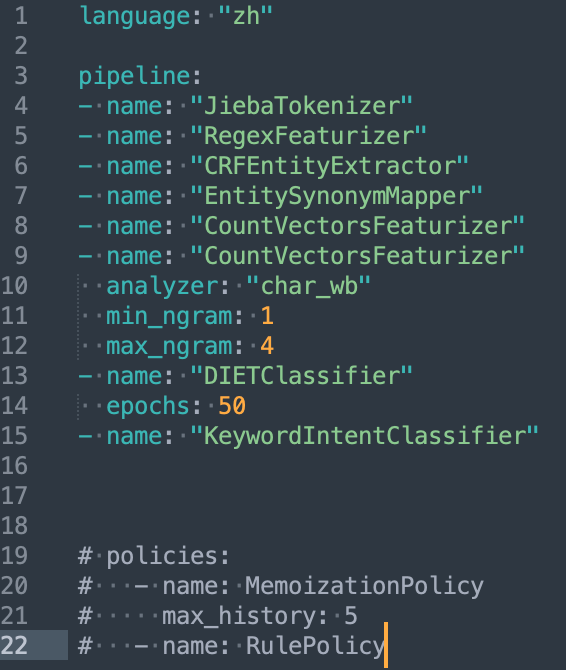

注意事项:
由于Keyword意图分类涉及python自带的re包,因此提出特定的版本要求:
1) Rasa 2.6.0 + Python 3.6(python 3.8报错)
2) 训练数据中可能出现标点符号问题(原句清洗),如中英文括号混用,将影响re的使用
3) 针对中文数据,需要将源码中re.search函数中pattern部分的r"\b"去掉
4) 通过消融实验发现,KeywordIntentClassifier
●在pipeline中需要放在主Classifier之后
●与Response Selector共同使用时,先后顺序不限,依然遵循上条规则
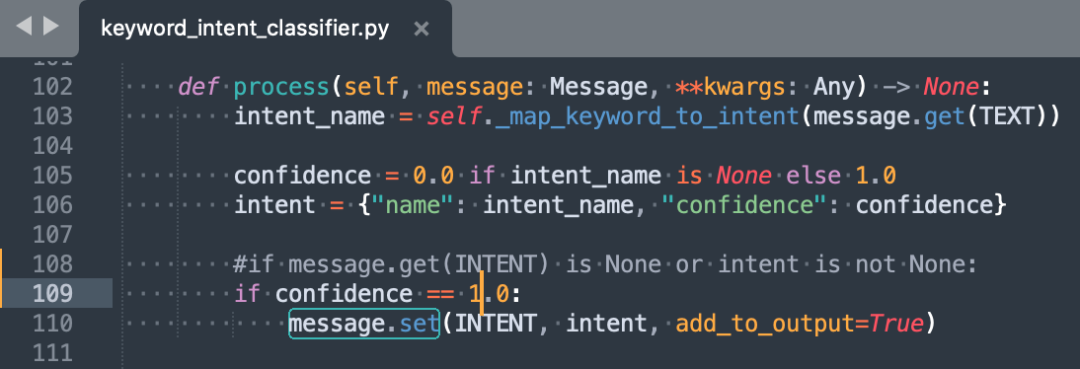
5) 由于Keyword意图分类器位置在pipeline后段,因此不论是否命中原句,其分类结果都将覆盖之前组件结果,因此对源码作如下更改,使得未命中原句情况下,Keyword分类结果不覆盖。这意味着,非原句将采用其他分类器的结果
3.1.6.3 核心代码解析
KeywordIntentClassifier类主要由train,process,persist和load四部分组成,
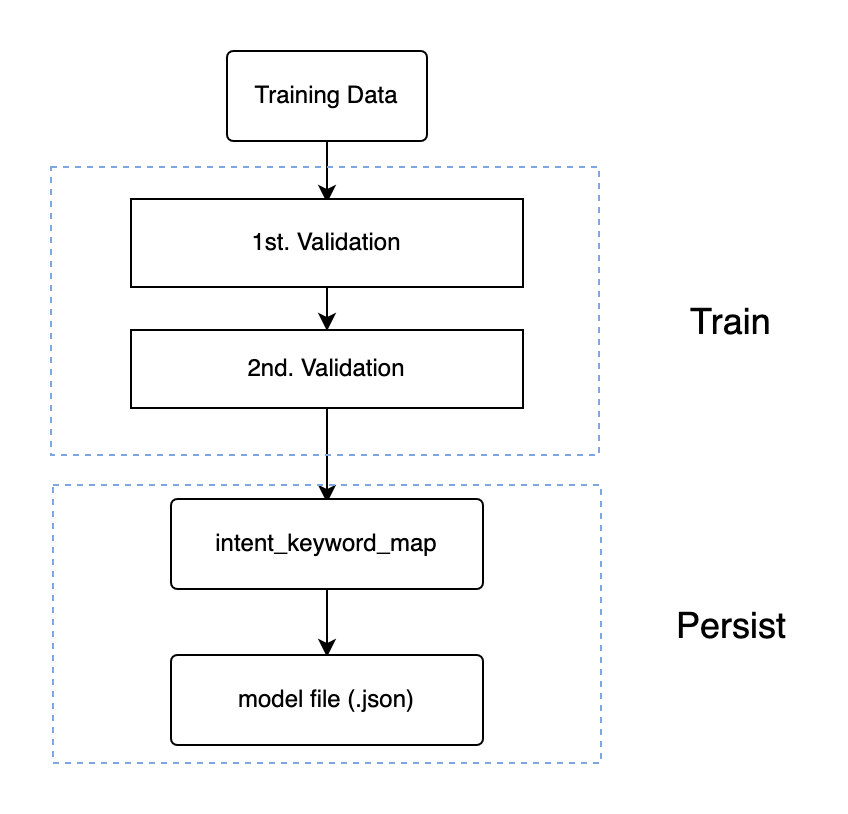
Train主要在训练中进行两轮数据验证,存在冲突的以下两类样本不被统计:
●相同文本归属不同意图
●子文本(被父文本包含)归属不同意图,此轮验证由子函数_validate_keyword_map实现
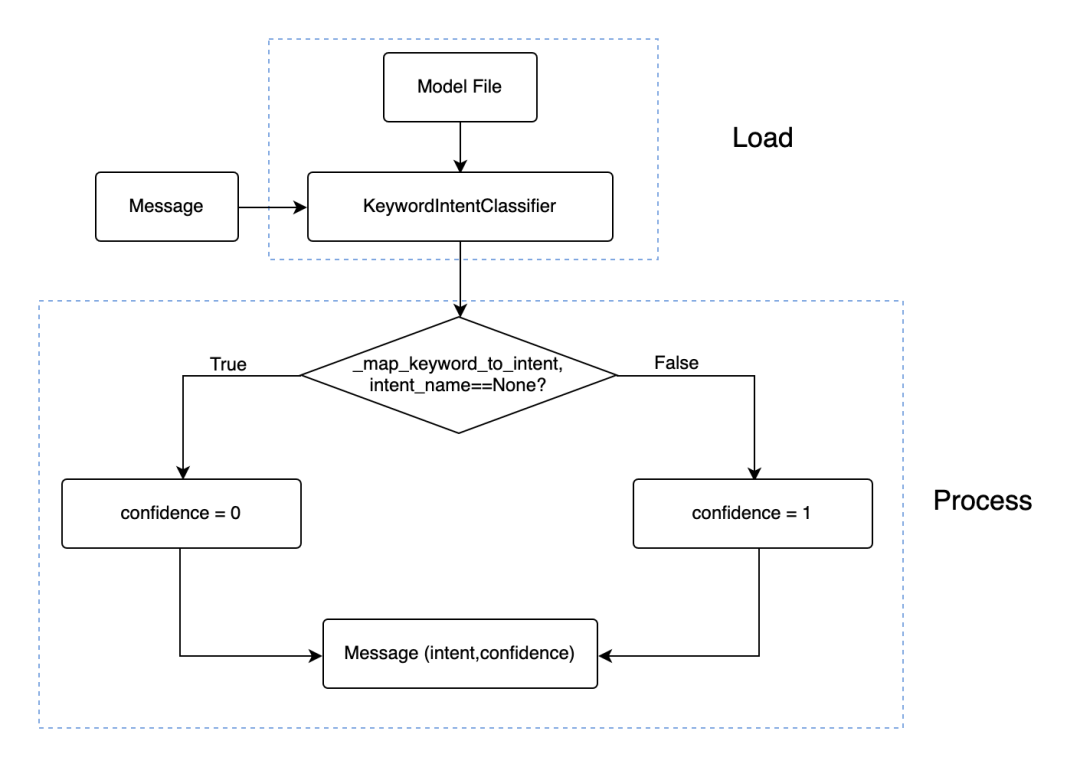
Process主要在训练后对输入的语句进行分类:
模型将输入Message与维护的intent_keyword_map进行比对:如果是原句,则返回查询到的意图,confidence置1;否则返回None,confidence为0,具体的比对任务由函数_map_keyword_to_intent完成。
Persist负责模型保存,即将所维护的intent_keyword_map存为json文件到指定位置
Load将从指定位置的文件中还原出KeywordIntentClassifier
P.S.
数据结构
intent_keyword_map {text1: intent1, text2: intent2,.....}
training_data.intent_examples [eg1, eg2,...]
eg1 {text: xxx, intent: yy, ...}
3.1.7 Fallback Classifier
3.1.7.1 工作机制
主要功能:当识别出的意图confidence过小或者是top2的两个意图confidence 很接近时,设置当前文本的意图为nlu_fallback。
Fallback_classifier 处理流程图:
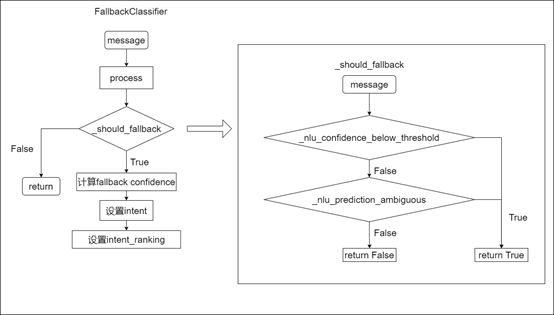
工作流程:
●用户message输入process
●调用_should_fallback函数进行判断是否需要设置成fallback意图
■_should_fallback 主要通过两方面进行判断:
1. 通过_nlu_confidence_below_threshold函数判断意图的最高confidence是否小于设置的threshold,如果小于,则直接返回True,否则,继续下一步判断。
2. 通过_nlu_prediction_ambiguous函数,首先判断意图个数是否大于等于2,如果否,则直接返回False,否则继续判断top 2 的两个意图confidence之差是否小于ambiguity_threshold,如果是则返回True, 否则返回False
●如果_should_fallback 返回False 则process 直接return,不进行fallback设置,否则,进行fallback_confidence的计算,并将其设置到message中
3.1.7.2 使用样例
分类器说明:
主要用于判断当前输入文本是否Intent 得分过小,或者排名靠前的两个得分相近。FallbackClassifier不能单独使用,需要在pipeline 中,使用FallbackClassifier之前配置其他的意图识别组件。
参数说明:
threshold: 意图阈值,如果所有的intent confidence 都小于这个阈值,则设置当前意图为 fallback
ambiguity_threshold: 模糊意图阈值,如果top 2 的阈值之差小于这个阈值,则设置当前意图为 fallback
参数默认值:
在rasa/core/constants.py中设置,threshold为0.3,
ambiguity_threshold为0.1

使用配置文件:
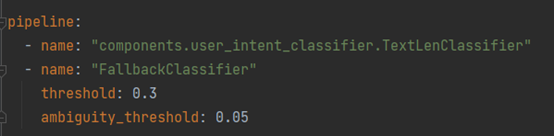
TextLenClassifier 为自定义的意图识别组件,基于用户输入文本的长度对其进行分类(主要用于配合FallbackClassifier进行demo设计)。
FallbackClassifier:
threshold 设置为0.3 ,ambiguity_threshold设置为0.05
3.1.7.3 核心代码解析
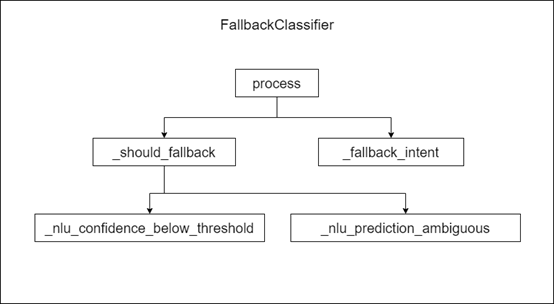
Fallback_classifier 函数调用关系图:
函数说明:
●def process(self, message: Message, **kwargs: Any) -> None:
FallbackClassifier组件入口函数
●def _should_fallback(self, message: Message) -> bool:
是否需要将意图设置为fallback
●def _nlu_confidence_below_threshold(self, message: Message) -> Tuple[bool, float]:
判断所有意图是否都低于配置阈值
●def _nlu_prediction_ambiguous(self, message: Message) -> Tuple[bool, Optional[float]]:
判断是否存在模糊的意图
●def _fallback_intent(confidence: float) -> Dict[Text, Union[Text, float]]:
格式化输出意图
FallbackClassifier样例代码包位置:
examples/fallback_demo
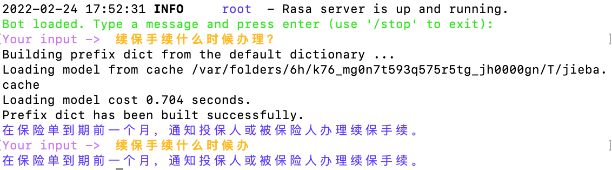
样例运行结果:
配置说明:
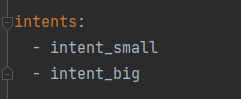
Domain配置:两个意图,intent_small, intent_big
Config配置:

模拟分类器-TextLenClassifier:
基于文本长度进行分类,设置不同的confidence,TextLen 小于 3时,intent_small为0.1,intent_big为0.2;TextLen 大于等3小于5时,intent_small为0.58,intent_big为0.6;TextLen大于5时,intent_small为0.7,intent_big为0.8。
运行结果展示:
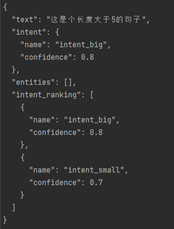
TextLen> =5
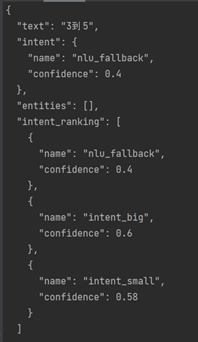
3<=TextLen<5
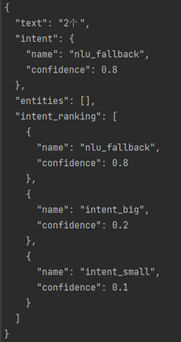
TextLen< 3

