

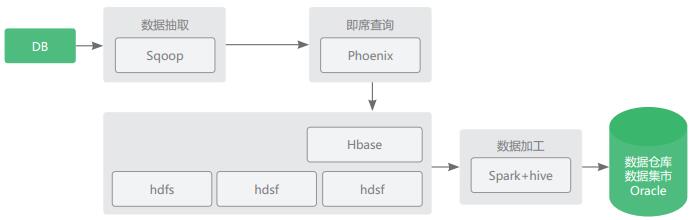
场景一:海量数据复杂分析
- 场景说明:对多张千万级以上表做关联分析。
- 优势:能够充分利用集群的并行计算能力
- 实现架构:
场景二:大表查询和分析
- 场景说明:单表 1 亿级以上数据复杂查询或批量分析。
- 优势:能够利用集群的并行计算提高查询速度,支持高并发、高吞吐查询。
- 实现架构:

场景三:海量历史数据存储
- 场景说明:关系型数据库中需要归档的历史数据存放到分布式文件系统 HDFS 中
- 优势:相对于共享储存廉价 ,相对带库使用方便
- 实现架构:

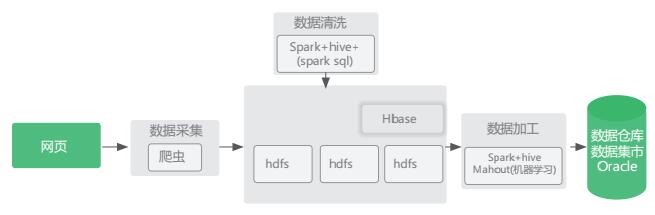
场景四:庞大的网页数据分析,如舆情分析、社会满意度分析
- 场景说明:基于网页数据做各种数据分析。
- 优势:大数据平台提供分布式存储、并行化计算框架、机器学习库。
- 实现架构:
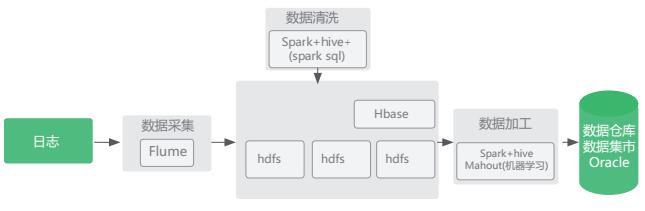
场景五:海量的日志数据分析,如用户体验优化、系统运行日志分析
- 场景说明:对海量日志数据做清洗、统计、分析。
- 优势:大数据平台提供分布式存储、并行化计算框架、机器学习库。
- 实现架构:
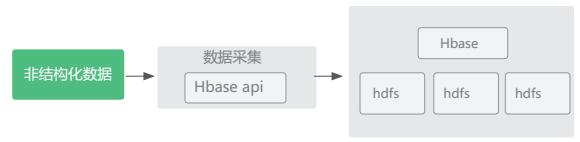
场景六:非结构数据存储
- 场景说明:海量的图片、视频、音频等非结构化数据存放到分布式文件系统 HDFS 中
- 优势:在分布式文件系统下存储可靠并使用方便
- 实现架构:
场景七:实时信息处理,如大屏神州数码信息展示
- 场景说明:高并发(每秒 5000 笔以上)的实时信息处理
- 优势:采集的数据不落地,基于内存的实时计算及查询
- 实现架构:




项目咨询
亲爱的朋友,如您对我们的产品感兴趣,您可以通过以下方式联系我们
联系方式
能让我们立即与您联系
服务热线:400-0762-660
快捷咨询
在线咨询
能让我们更好的交流
也可扫一扫,详细填写您的详细需求,我们将尽快联系您






 京公网安备11010802043876
京公网安备11010802043876





