

人工智能NLP技术
在12345智能派单中的应用研究
神州控股
陈武练

1.
12345政务便民服务热线对智能派单的需求
12345政务服务便民热线(简称12345热线),指各地市人民政府设立的由电话12345、市长信箱、手机短信、手机客户端、微博、微信等方式组成的专门受理热线事项的公共服务平台。
某市“12345政务服务便民热线”建立了完整的数字化平台,客服人员通过标记热线信件的类别,将信件分派给对应的部门进行处理。在实践中,这项分派工作存在着信件多、工作量极大、人工分派不及时、审核误分类、误判断处理部门以及引起的重新分派、转发时间延误,对各信件的及时处理造成了不同程度的影响,非常需要采取改进措施以便为市民提供更优质的服务。
2.
解决方案
12345的信件数据汇总到数字化平台后表现为文字和图片,客服人员主要通过阅读信件内容来判断应该分派给哪个部门。因此,采用人工智能中的NLP(NLP,Natural Language Processing)自然语言处理技术来对信件进行智能派单是最合适的。我们运用该技术在这方面进行了积极的研究和尝试,并取得了重要的技术验证成果。下面将对这一研究过程和成果进行介绍,主要包括:确定训练目标、模型选择、数据清洗、模型训练、模型评估、模型预测等。
(一)训练目标
我们的目标是通过对优选的深度学习模型进行微调,让模型能根据12345信件的内容自动判断该信件由哪个部门进行处理最合适,并自动分派到该部门,从而提高派单工作的效率。
(二)模型选择
BERT的全称是Bidirectional Encoder Representation from Transformers,即双向表征的预训练语言模型。该模型由Google在2018年提出,获得了计算语言学协会(NAACL)北美分会2019年年度会议最佳长篇论文奖,在11个NLP任务上的表现刷新了记录,是目前在NLP领域最好用的模型之一。BERT模型能记忆海量事实并轻松完成诸如文字分类、摘要生成、阅读理解、人机对话等任务。根据训练目标,我们要完成文字分类任务,分析后采用基于BERT中文预训练模型“bert-base-chinese”的文本分类模型“Auto Model For Sequence Classification”进行信件分类训练。
(三)数据清洗
本节所用主要工具:Python3.9、Numpy1.21.5、Pandas1.4.1
1. 数据探索
我们初步探索了数据,对部门信件总数统计如下(部分):
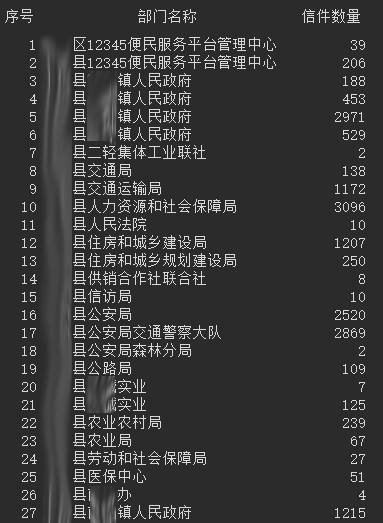
...

我们发现12345信件数据有如下特点:
(1) 涉及部门极多,达到1000+个部门;
(2) 市直部门和区直部门数据共存
(3) 出现了部门改革前后新老部门名称共存的数据
(4) 出现了大量处理部门为乡镇府和镇政府的数据
(5) 出现了大量处理部门为第三方平台的数据
(6) 出现了部分处理部门为国有企业的数据
(7) 部分数据的部门名称不规范
(8) 有些处理部门的数据量极少
这些数据要能真正用于模型训练,还需要进行清洗。
2. 清洗措施
我们先对原始数据脱敏,去除个人、法人敏感信息,然后根据12345业务场景对脱敏数据进行有针对性的分析,采取了合并、替换、部分保留、抛弃等不同的清洗处理措施,并根据需要进行字段抽取和数据重构,对目标值重新编码,得到了最终适合训练的数据集。
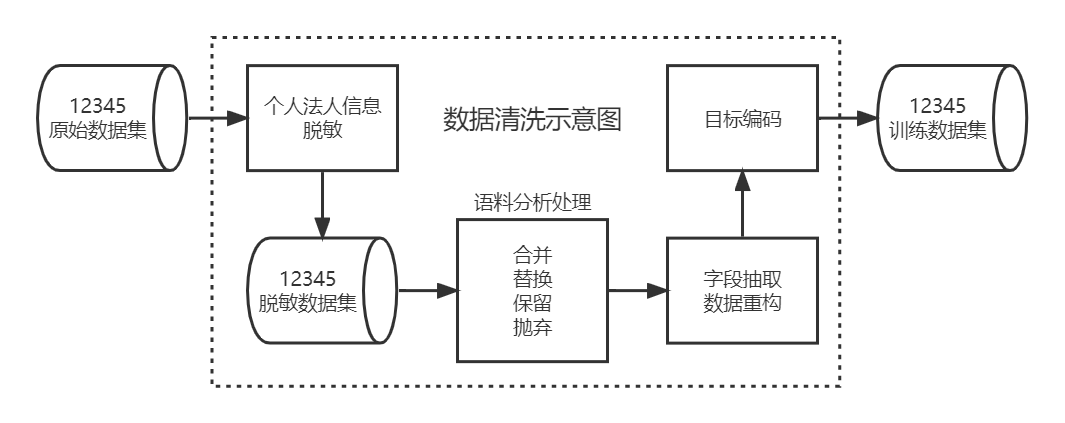
抽取部分样例数据显示如下:

(四)模型训练
本节所用主要工具:
i7 9700 32G+NVIDIA 2080Ti 11G+CUDA11.6、PyCharmCE 2020.1.1、Python3.9、Numpy1.21.5、Pandas1.4.1、Scikit-Learn1.0.1、Pytorch1.9.1、Transformers4.18.0
我们将数据分为两份,一份作为训练集,另一份作为验证集,设置每个batch加载8个记录,将预训练模型加载到显卡,按不同参数组配置不同的学习率,采用AdamW优化函数及线性学习率预热进行训练:
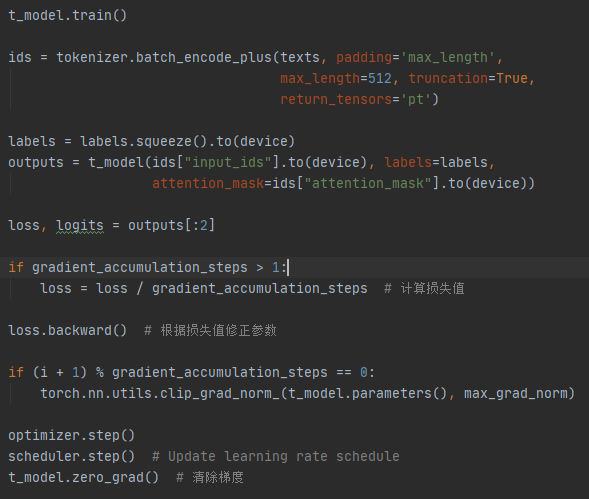
经过2小时12分,完成全部训练。
(五)模型评估
以下是我们从验证集中随机抽取3800条数据对已训练好的模型进行验证,其评估报告如下:
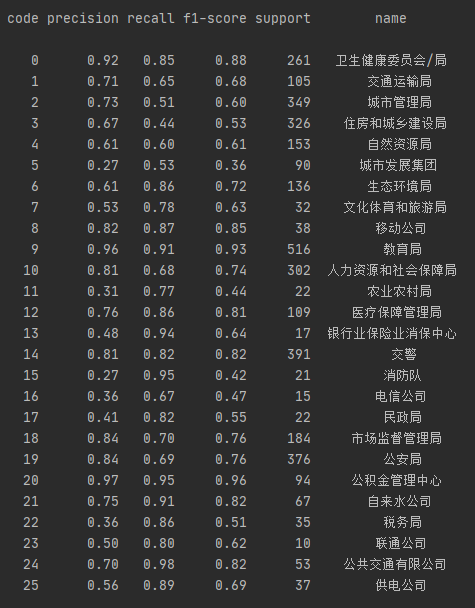
图:总体分类评估报告
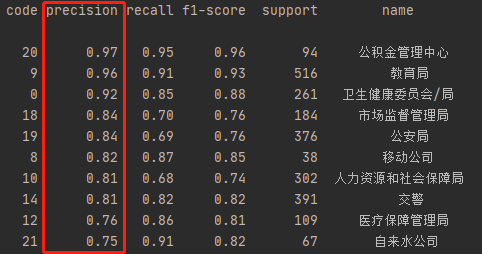
图:查准率(precision)最高的前10名部门名称
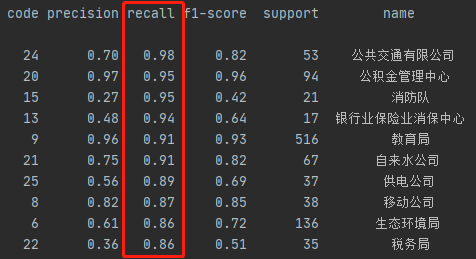
图:查全率(recall)最高的前10名部门名称
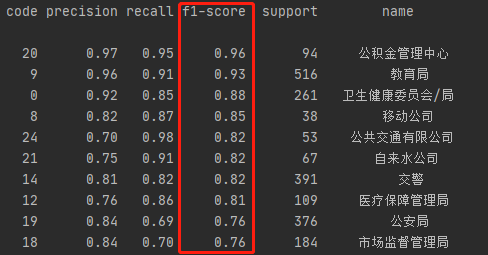
图:F1分数(f1-score)最高的前10名部门名称
我们可以看到模型在信件分类中的查准率、查全率以及F1分数上都有较好的表现,特别是公积金中心、教育局、卫健委/局、移动公司、公交公司、公安局、市场监管局、人社局、医保局、交警等重要部门的信件,模型的分类效果均达到或超出预期。
(六)模型预测
我们从某市12345平台(http://12345.longyan.gov.cn/)的公开件中随机抽取了20条信件记录,用训练好的模型对其处理部门进行预测,并对照12345平台的最终处理部门来判断模型的预测是否正确。结果发现模型全部预测正确,取得了相当不错的效果。预测情况部分截图如下所示:


3.
结语
针对12345派单中存在的难题,我们运用人工智能自然语言处理NLP技术,通过对原始数据的脱敏、清洗、重构得到了适合BERT模型的训练数据集,在此基础上训练出了能对信件进行自动分类的智能模型。经过验证,该模型在查准率、查全率、F1分数综合性能的各项指标上都取得了很好的成绩,以后将在生产环境中应用起来。


 京公网安备11010802043876
京公网安备11010802043876