

金融电子化 | 神州信息:一种轻量、高效的分布式核心建设思路
- 发布时间:2022-06-29
- 来源:
- 大 中 小
- 打印




蓦然回首,那人却在灯火阑珊处
——一种轻量、高效的分布式核心建设思路
在探讨分布式核心的建设之前,我们首先需要分析一下银行对核心业务系统的诉求。当前背景下核心系统的建设有一个非常重要的前提条件——信息技术应用创新,也就是现阶段建设核心系统都必须要考虑单个服务器的稳定性以及单个数据库的可靠性。另外,我们再从核心系统自身来看,最基本的需求就是稳定可靠,其次,还有如何快速创新、提升处理能力等改善性需求。
数据层的分布式对核心系统整体架构有着重要影响
今年北京金融科技产业联盟发布的《商业银行分布式联机交易系统技术规范》中提到,分布式应该覆盖的范围主要包括微服务平台、分布式数据、分布式缓存访问、分布式消息访问、分布式调度及分布式事务六个维度,在这其中“分布式数据”对整体架构有着非常重要的影响。
分布式数据,很多人都认为其是解决大数据量的问题,甚至有些小的银行都认为其没必要进行数据层的分布式。其实这样的理解也无可厚非,因为“分布式数据”的初衷就是将大数据量表的数据进行水平切分,用多个数据库承载,以解决单库数据量过高的问题,由于其将数据分散到多个不同的数据库进行存储,即使是其中一个数据库集群全部宕机,对交易的影响也只是几分之一,大幅提升了数据的高可用,这在当前背景下对核心这种关键类业务系统非常重要。同时,分布式数据库还与同城双活架构有着非常重要的关系。
数据层的分布式解决方案百花齐放
在数据层分布式的具体落地方案中,很多银行都有自己不同的选择,典型的代表如下。
1.分布式数据访问组件。某国有大行自2015年开始进行分布式转型,到目前已经实现了完整的分布式技术体系,并且已经有了大量的实践经验,数据层分布式的一种典型方式就是采用完全自研的分布式数据访问组件,底层直接对接MySQL数据库,其中信用卡核心已经基于该架构实现10亿级账户的稳定运行,具有重要的参考价值。
2.分布式数据中间件。某股份制银行在2018年开始研发自己的分布式技术平台,数据层的分布式采用的是中间件的模式,目前已经将现有核心系统的流量同步复制到分布式核心上进行验证,后续将择机进行分布式核心的分批投产。
3.分布式数据库。另一股份制银行的核心分布式下移选择了一条比较有特色的路线,其采用自研的工具将AS/400上的代码直接转换为Java代码,同时直接引入GoldenDB分布式数据库来解决数据层的分布式。论证了分布式数据库是可以应用到银行的关键业务系统。
4.单元化架构。单元化强调将数据按一定的维度拆分为多个单元,所以其本质还是数据分布式的一种实现方式。今年某国有大行的新一代个人业务核心系统投产。其将行内的核心系统拆分为多个独立的单元,在所有服务访问时,首先通过全局路由映射确认在哪个单元,然后再发起到具体单元的访问,如果涉及跨单元的数据查询,则通过其他的架构配合完成。该模式各单元之间完全独立,相互影响较小,但同样因为其完全独立,对应用功能的实现及系统架构会带来一定的复杂度。
5.本中心优先的分布式数据访问。作为某省会级城商行,对该级别的银行也是有重要的参考意义,其引入厂商完整的分布式技术体系,虽然数据量并不是很大,但也通过分布式数据访问组件的方式对数据进行了拆分,并通过中心级优先访问的策略,不仅实现了同城两个中心的读写多活,还最大限度地提高访问效率,同时规避了单元化架构带来的跨单元数据查询的复杂度。
几种方案中,分布式数据访问组件、分布式数据中间件、分布式数据库都强调对业务尽可能的透明,单元化则完全是一种架构层面的解决方案,目前来看对业务的侵入度还比较高。金融机构在建设分布式核心系统时需要根据自己的实际情况进行合理选择。
一种轻量、高效的分布式核心架构实践
在分布式核心建设过程中,大家对微服务的使用已经基本达成共识,由之前仅仅是将核心业务系统进行拆分,到目前结合中台的理念,首先抽象出多个不同业务领域的能力中心,再由能力中心快速组合完成相关业务功能的实现,不仅提高了整个核心业务系统的高可用及处理能力,同时也将敏捷的理念发挥到极致,对后续的业务持续快速创新提供了基础。下面从最基本的数据层分布式方案进行推演,以实现一种对大部分银行都适配的解决方案。
基于分布式的理念,把数据按照一定的维度进行水平拆分,假设总共有 4000万的账户数据,按照客户号拆分为 4 个分片,每个分片有 1000 万的数据,每个分片用一个分库来承载,如图 1 所示。
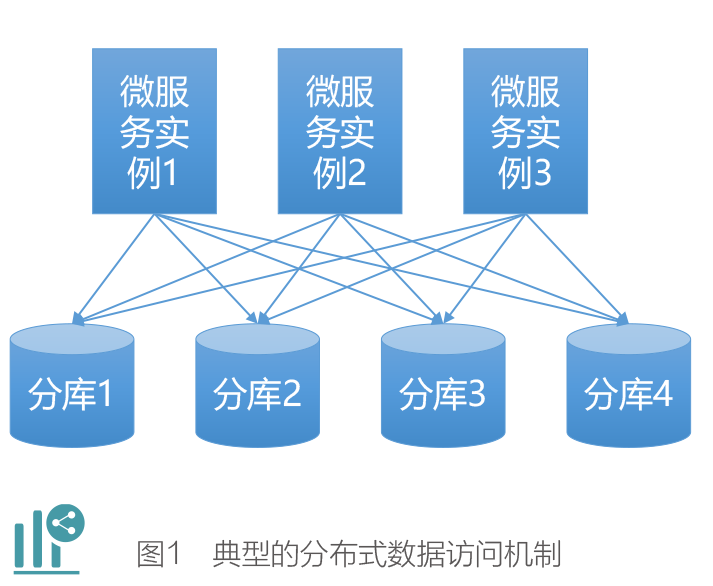
如果采用的是分布式数据访问组件的模式(行业典型的开源实现是Sharding-JDBC),通过其可以快速实现指定账户的信息修改、查询、存入 / 支取等常规交易,这种 SQL 请求都会直接路由到具体的分库中进行操作;对于不含客户号的交易(例如查询一个月之内开立的账户),不管是从哪个实例中发起的请求,该模式都可以并行给多个分库发起查询指令,然后其内部会将各个分库的查询结果进行合并处理并返回,整个过程对业务开发人员完全透明;对于转账交易可以理解为存入与支取的组合,只需要配合相关的分布式事务处理机制即可快速实现。这种模式一般都支持分库和分表组合的方式,具体的分片数可以通过分库与分表的组合灵活处理,假如有32 个分片,可以分为4 个分库,每个分库又有8 个分表的方式来实现,所以理论上其支持亿级数据量,采用MySQL数据库都是没问题的,并且还可以将分库数控制在一个相对合理的范围。上述的机制,如果在一个数据中心内几乎可以满足我们的所有需求,但作为核心业务系统,需要在更高的维度考虑其高可用,所以至少必须做到同城多活。这里的多活是包括数据层的读写多活,我们将上述的运行机制平移到同城两个数据中心进行分析。
将 4 个分库平均分到同城的两个中心, 假 设 分 库 1、2 在 IDC1, 分 库 3、 4 在 IDC2,当隶属于分库 1 中的账户从 IDC1 中的微服务实例中发起交易请求,其内部将请求快速路由到本中心的分库 1 中进行 SQL 处理,但如果该交易请求从 IDC2 中的微服务实例中发起,则需要跨数据库中心去访问 IDC1 中的分库1,这样就会造成额外的跨数据中心的网络开销。如果该交易中只有 1~2 条 SQL影响也不大,但如果该交易中包括 20 条SQL,每一条都涉及跨数据中心的访问,则累计的网络开销就有1ms×20,约有20ms 的额外损耗,再按照概率大致计算,基本有50% 的交易面临这种可能,整体对核心业务系统的性能影响比较明显。但上述问题其实只需在技术层面做一点增强就可以解决:在服务执行之前先判断一下其操作的数据是在哪个分片,然后再将其转发到正确的IDC 即可,如图2所示,红色部分可以理解为前面提到的跨中心路由功能。同样假设上述从 IDC2 进来的交易请求访问的是分库 1 中的数据,则通过简单的计算,发现其要操作的数据在 IDC1 中,则将该请求直接转发到 IDC1即可,后续所有操作都在 IDC1 内部完成。这样问题就解决了,并且对跨多个分片的数据查询及转账等业务场景,其固有的优势还可以保留,相比单元化的方式要简单很多。
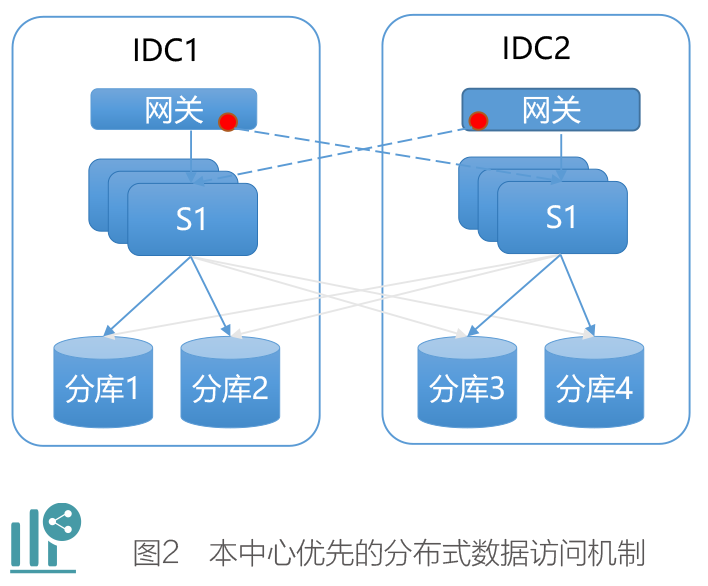
这种机制不管是采用分布式数据访问组件的方式实现,还是基于类似 TDSQL、 GoldenDB 这种类型的分布式数据库都可以实现,区别只是数据的分布式处理在整体架构中的位置不同而已。该模式已经在多家城商行落地实践,不仅充分发挥出了分布式的优势,在开发复杂度及建设周期等方面也体现出了优势。
分布式的下一站
目前国内大部分银行还在进行集中式向分布式的转型,我们认为分布式未来的发展一定会与云原生进行融合,将微服务等支撑技术进一步下沉到基础设施,进一步实现技术与业务的解耦,使核心系统的建设更加关注业务本身,底层的技术支撑及运维由底层的云原生基础设施去处理,实现更加精细化的分工,进一步推进金融行业的数字化转型。
■作者:神州信息工程院副院长首席架构专家 薛春雨






 京公网安备11010802043876
京公网安备11010802043876





